|
Page 1, 2
The Center of Excellence in Generative Medicine (COEGM) at the University of Bridgeport College of Naturopathic Medicine is rapidly becoming the leading research and industry leader in naturopathic clinical bioinformatics. Much of the utility and pertinence of the software solutions produced by the COE lies in its recognition that today's physicians cannot easily parse increasingly available large datasets (such as produced by genome or microbiome reporting services) in any sort of real-time efficient manner. This is indeed a dilemma, as 'big data' approaches (in particular those employing machine learning algorithms) are increasingly pointing the way to the possibilities of more precise treatment based on high-value considerations.
 Townsend Letter provides a platform for those examining and reporting on functional and integrative medicine. Please support these independent voices. Townsend Letter provides a platform for those examining and reporting on functional and integrative medicine. Please support these independent voices. |
One possible approach to the problem was a more 'generative' approach, as advanced by William Wimsatt: That we are limited beings and the world we try to understand is complex.1 For Wimsatt, robustness (believing that a particular apple exists because we can see it, feel it, smell it, taste it, and hear it crunch when we eat it) is measured by the multidimensionality of the data models: The more we can detect things in multiple ways, the more we are inclined to believe they exist. Closely connected to robustness are the heuristics, rules of thumb that we use to think about the world and which are foundational to his epistemology.
 Heuristics can be wrong or biased but tend to work well when applied to what is robust in the world. For example, a basic generative heuristic is derived from cybernetics and is known as 'law of requisite variety.' In essence, it mandates that the number of states of a control mechanism must be greater than or equal to the number of states in the system being controlled. This heuristic, along with personalized clinical data and robust molecular network data, permits the design of computationally generated, personalized, multi-axis polypharmacy, well-suited for natural products, where the therapeutic index of the agent combination rises significantly, but the overall safety profile remains essentially unaltered. Heuristics can be wrong or biased but tend to work well when applied to what is robust in the world. For example, a basic generative heuristic is derived from cybernetics and is known as 'law of requisite variety.' In essence, it mandates that the number of states of a control mechanism must be greater than or equal to the number of states in the system being controlled. This heuristic, along with personalized clinical data and robust molecular network data, permits the design of computationally generated, personalized, multi-axis polypharmacy, well-suited for natural products, where the therapeutic index of the agent combination rises significantly, but the overall safety profile remains essentially unaltered.
The generative paradigm works well in addressing the challenge of how to approach the onslaught of 'big data' into the clinical workspace. Person-specific genomic, metabolomic, and microbiome data files can easily reach into the hundreds of megabytes of information. Clearly, we need analytic tools capable of automating the basic handling, analysis, and integration of this wealth of information. The challenge is daunting, but the potential rewards are almost unfathomable: A more precise clinical impression, where (paradoxically) 'more data is better than better data,' and broadly applied evidence-based conclusions are only one part of the evaluation framework.
Over the past five years in partnership with Datapunk Bioinformatics LLC, the COEGM has developed a variety of computational tools for precision medicine using generative-based algorithms; some proprietary, such as the well-known and regarded Opus23 genomic development platform, along with its two add-on analytic modules, Utopia (microbiome) and Icarus (metabolome). Other apps on the servers are open source and free-to-use.
On August 25, 2018, the COEGM announced the release of 'Circuits' a gene-based open source platform combining genomic data in a variety of robust dimensions. Circuits is web-based, has an imaginative and intuitive user interface, and is free to use. I'd like to use the rest of this article to introduce and describe the capabilities of Circuits and invite the readers of the Townsend Letter to explore its possibilities.
The Interface
Circuits resides at the web address https://www.datapunk.net/circuits and can be accessed by anymodern browser. Because of the data depiction density, it is not optimized for small handheld smart phones, and it is recommended that a desk or laptop machine be used to access the app.
Circuits: Main Window
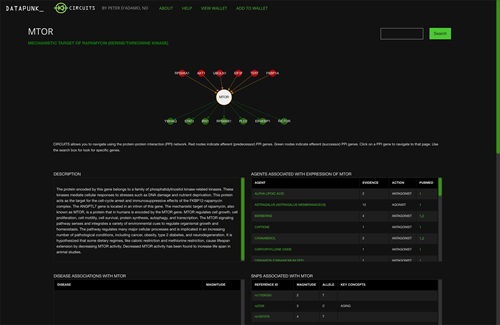
Circuits' initial presentation appears as shown below. In its default state, Circuits displays the data for the gene MTOR (mammalian target of rapamycin) as a place-filler. Immediately below the title slug, Circuits displays the known PPI (protein-protein interactions) associated with the target gene (in this case MTOR) as a Cytoscape network. Afferent nodes are shaded red whilst efferent nodes are colored green. This network is an effective way to navigate Circuits as any node will bring up its related gene and load it into the main window. Users can also search for any gene/protein by using the traditional search input at the top right of the screen. To help users refine their query, the search feature will autocomplete over 30K currently recognized gene symbols.
Scrolling downwards, the user will see the six scrollable panes that contain the data mash-ups. From the top left we can see a detailed description of the gene, and across from that, a pane that depicts the available data on agents associated with the expression of the gene. This is a unique, human-curated database that was originally developed for use with the Opus23 platform.
Circuits employs a variety of modal popups to provide additional contextual data. Clicking on any agent will trigger a popup window that draws a unique radar plot that we call the 'genomic logo' of the agent. This logo depicts the strength, action, and targets of the indicated agent, using a complex algorithm based on study design, scope, and subject type.
The next row of two panes further down show disease associations and clinically relevant SNPs (single nucleotide polymorphisms) associated with the target gene. Pathology data is derived from ClinVar, OMIM and GWAS, while SNP associations are from GWAS and the exclusive human-curated SNP database developed for use in the Opus23 program. Clicking on a hyperlinked disease or SNP will also launch informational popups.
The next row of panes highlights, on the left, any adverse drug reactions linked to specific polymorphisms of the target gene and known tissue and organ distributions of the target gene. As with all internal hyperlinks, clicking on any link in these panes will trigger a popup containing additional data.
The next row of informational panes shows, on the left, pathway regulations associated with the target gene pathway and its effect (either up-regulation or down-regulation). The bottom right pane shows etiological links associated with the target gene that are inferred via the target gene's disease associations.
The final single pane displays HMDB (Human Metabolome Database) linkages to the target gene. Clicking on the metabolite common name will trigger a popup display detailing the metabolite.
The Data
Most of the data used by Circuits was developed initially for use by the Opus23 application from publicly available repositories. Exceptions include the SNP and agent expression datasets, which were developed entirely by Datapunk human curators. The PPI, etiome, and diseaseome datasets were enriched by combining multiple source data, in some cases programmatically through structured machine earning. A few of the larger sources are listed as references.2-8 It should be noted that the publication date of several of the references may be over several years old; however, these articles typically announce and describe the dataset, the actual databases they represent are almost all continuously updated; and through its network of application programming interfaces (APIs), so is Circuits.
Page 1, 2
|